How to Install DeepSeek Locally [R1, V3]
A complete step-by-step guide to install DeepSeek on your local machine, including Mac and Windows
Leave email, get notified when one-click install version is ready!
Local DeepSeek is built on the shoulders of giants







Why Choose Local DeepSeek
Get all advantages of DeepSeek with security and high performance of local deployment
No API or Cloud Limits
You're in full control—no third-party restrictions or reliance on the cloud
Privacy and Control
Your data stays private, running entirely on your own infrastructure, not someone else's servers
Speed and Scalability
Experience fast performance with low latency, especially when running smaller models
ChatGPT-like UI
Get a sleek, modern chatbot interface—no messy terminal required
Installation on MacOS
The fastest way to run DeepSeek on MacOS
Step 1. Install Ollama -- AI Model Manager in MacOS
Prerequisites
Ollama for MacOS Requires macOS 11 Big Sur or later
First, we need install Ollama—the AI Model Manager that powers local AI models.
If you don't already have Python, you might need to install it first.
Install Ollama:
Option 1: Using Bash
/bin/bash -c "$(curl -fsSL https://ollama.com/download)"
Option 2: Download from https://ollama.com/download/mac
When downloaded, run the installer and follow the setup instructions in the following screen.
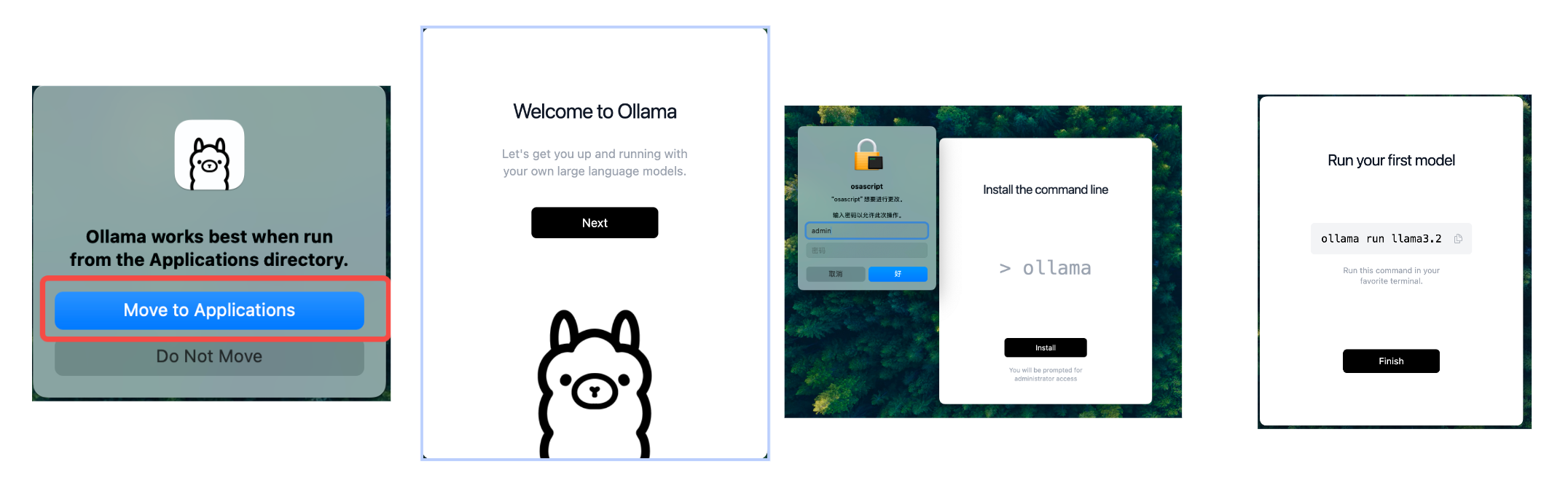
Verify the installation:
Open Terminal and run:
ollama --version
If that runs without errors, and show information about ollama version, you are good to go!
ollama version is 0.5.7
Step 2. Download DeepSeek R1
Notice: Mac OS with M-series chip does not support 167B deepseek R1model
DeepSeek R1 comes in multiple sizes.
💡 Bigger models = smarter AI, but also slower performance.
Choose the right size based on your Mac hardware:
| Model | Best RAM | CPU Required | Best Use Case |
|---|---|---|---|
| 1.5B | 8GB+ | Any modern CPU | Basic writing, chat, quick responses |
| 8B | 16GB+ | M1 | General reasoning, longer writing, coding |
| 14B | 32GB+ | M2 | Deeper reasoning, coding, research |
| 32B | 64GB+ | M3 or M3 Pro | Complex problem-solving, AI-assisted coding |
| 70B | 64GB+ | M4 orM4 Pro | Heavy AI workflows, advanced research |
| 167B | 512GB+ | only on Nvidia GPU | multiple GPUs: A100 or H100 |
ollama pull deepseek-r1:8b # Fast & lightweight
ollama pull deepseek-r1:14b # Balanced performance
ollama pull deepseek-r1:32b # Heavy processing
ollama pull deepseek-r1:70b # Maximum reasoning, slowest speed
Step 3. Run DeepSeek R1
To test the model inside the terminal:
ollama run deepseek-r1:8b
Now, you can chat with DeepSeek directly inside the Terminal.
Installation on Windows
The fastest way to run DeepSeek on Windows
Step 1: Install Ollama
- Download Ollama for Windows from https://ollama.com/download/windows.
- Run the installer and follow the setup instructions.
Verify the installation:
ollama --version
If that runs without errors, youre good to go!
Step 2: Install DeepSeek-R1 32B Model
Once Ollama is installed, run the following command to download and prepare the model:
DeepSeek R1 comes in multiple sizes.
💡 Bigger models = smarter AI, but also slower performance.
Choose the right size based on your Windows hardware:
| Model | Best RAM | CPU Required | Best Use Case |
|---|---|---|---|
| 1.5B | 8GB+ | Any modern CPU | Basic writing, chat, quick responses |
| 8B | 16GB+ | 4+ Cores | General reasoning, longer writing, coding |
| 14B | 32GB+ | 6+ Cores | Deeper reasoning, coding, research |
| 32B | 64GB+ | 8+ Cores | Complex problem-solving, AI-assisted coding |
| 70B | 64GB+ | 16+ Cores | Heavy AI workflows, advanced research |
| 167B | 512GB+ | only on Nvidia GPUs | multiple GPUs: A100 or H100 |
ollama pull deepseek-r1:8b # Fast & lightweight
ollama pull deepseek-r1:14b # Balanced performance
ollama pull deepseek-r1:32b # Heavy processing
ollama pull deepseek-r1:70b # Maximum reasoning, slowest speed
3. Run DeepSeek R1 (Basic Mode)
To test the model inside the terminal:
ollama run deepseek-r1:8b
Now, you can chat with DeepSeek directly from the terminal.
FAQ About Local DeepSeek
Have another question? Contact us on Discord or by email.
Which version of DeepSeek R1 should I choose?
If you have got a powerful GPU or CPU and want top-tier performance, go with the main DeepSeek R1 model. If you’re working with limited hardware or want faster generation, the distilled variants (like 1.5B, 14B) are a better fit.
Can I run DeepSeek R1 in a Docker container or on a remote server?
Absolutely! As long as you can install Ollama, you can run DeepSeek R1 in Docker, on cloud VMs, or on on-prem servers.
Is it possible to fine-tune DeepSeek R1 further?
Yes! Both the main and distilled models are licensed for modifications and derivative works. Just make sure to check the license details for Qwen- and Llama-based variants.
Do these models support commercial use?
Yes, the DeepSeek R1 models are MIT-licensed, and the Qwen-distilled versions are under Apache 2.0 from their original base. For Llama-based variants, check the Llama license specifics. They’re all relatively permissive, but it’s a good idea to read the license terms to confirm if your use case is covered